Stable Diffusion 3.5 is the latest iteration in AI image generation technology, offering enhanced performance, better prompt understanding, and compatibility with systems that have limited video RAM. With advancements in model architecture and text encoders, this version enables creators to produce high-quality images quickly and efficiently. This guide provides an in-depth overview of Stable Diffusion 3.5 Large Turbo, including its features, setup process, and practical workflow using ComfyUI.

Table of Contents
What Is Stable Diffusion 3.5?
Stable Diffusion is a cutting-edge generative AI model designed for text-to-image synthesis. The 3.5 version introduces several improvements over its predecessors, including:
- Improved Prompt Understanding:
The integration of T5 text encoders enhances the model’s ability to interpret complex prompts and relationships between elements. This makes it easier to generate images that align closely with user descriptions. - Higher Resolution Outputs:
Stable Diffusion 3.5 generates images at a native resolution of 1024×1024, delivering cleaner and sharper results compared to previous versions. - Optimized for Speed and Performance:
The “Turbo” designation indicates that this model is optimized for faster execution, even on systems with limited GPU memory. - Modular Design:
Unlike earlier versions, the text encoders (clip_g,clip_l, andt5xxl_fp8) are not included in the main checkpoint file. This modular approach allows users to customize their setup based on hardware constraints.
What Do FP8 and FP16 Mean?
When working with AI models like Stable Diffusion 3.5, terms like FP8 and FP16 refer to floating-point precision, which determines how numbers are represented and processed in the model. Here’s a quick explanation:
- FP8 (Floating Point 8-bit):
FP8 uses 8 bits to represent numbers. It is a highly efficient format that reduces memory usage and computational requirements. Although FP8 offers lower precision compared to FP16, it is ideal for models optimized for speed and hardware with limited resources, such as Stable Diffusion 3.5 Large Turbo. This makes it particularly useful for systems with lower video RAM. - FP16 (Floating Point 16-bit):
FP16 uses 16 bits to represent numbers, providing higher precision than FP8. While FP16 requires more memory and computational power, it is often used in situations where numerical accuracy is critical, such as training large AI models or generating highly detailed outputs.
In the context of Stable Diffusion 3.5, the text encoder T5 XXL FP8 utilizes FP8 precision to balance performance and hardware efficiency, making it suitable for a wide range of devices.
Suggested GPU Memory to Run Stable Diffusion 3.5
Stable Diffusion 3.5 requires varying amounts of GPU memory depending on your intended use, such as image resolution, batch size, and whether optimizations are applied. Here’s a quick summary:
Summary of GPU Memory Requirements
- Minimum (8 GB):
- Works with heavy optimizations like FP16 and xFormers.
- Suitable for generating lower-resolution images (e.g., 512×512) with a batch size of 1.
- Limitations: Cannot handle high resolutions (1024×1024) or complex pipelines.
- Recommended (12–16 GB):
- Ideal for standard resolutions (512×512 or 768×768) and moderate features (e.g., inpainting, ControlNet).
- Supports batch sizes of 1–2 and higher resolutions (up to 1024×1024).
- Examples: NVIDIA RTX 3060 (12 GB), RTX 3080 (10–12 GB), RTX 4070 (12 GB).
- Optimal (16–24 GB):
- For generating high-resolution images (1024×1024 or higher), advanced features, and larger batch sizes (4–8 images).
- Examples: NVIDIA RTX 3090 (24 GB), RTX 4090 (24 GB).
- Professional (>24 GB):
- For researchers or production environments requiring very high resolutions (e.g., 2048×2048), fine-tuning, or training models.
- Examples: NVIDIA A100 (40 GB), H100 (80 GB).
Where to Download Stable Diffusion 3.5 Files
To set up Stable Diffusion 3.5 Large Turbo, you’ll need to download the required files from Hugging Face repositories. Below are the direct links:
1. Stable Diffusion 3.5 Large Checkpoint
- File Name:
sd3.5-large_turbo.safetensors - Download Link: Stable Diffusion 3.5 Large Turbo Checkpoint
2. Text Encoders
- Clip G Encoder:
clip_g.safetensors- Download Link: Clip G Encoder
- Clip L Encoder:
clip_l.safetensors- Download Link: Clip L Encoder
- T5 XXL Encoder (FP8):
t5xxl_fp8.safetensors- Download Link: T5 XXL FP8 Encoder
Setting Up Stable Diffusion 3.5 Large checkpoint
Step 1: Organizing Files
After downloading the required files, organize them in your ComfyUI directory as follows:
- Checkpoint File:
Placesd3.5-large_fp8_scaled.safetensorsin/models/checkpoints/.
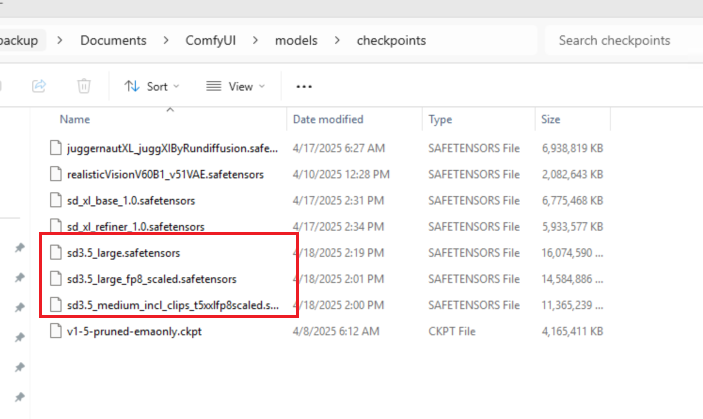
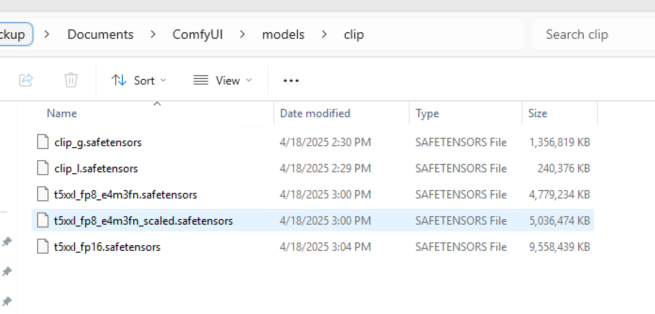
- Text Encoder Files:
Placeclip_g.safetensors,clip_l.safetensors, andt5xxl_fp8_scaled.safetensorsin/models/clip/.
Step 2: Restart ComfyUI
Restart ComfyUI to ensure the newly added files are loaded correctly.
Workflow for Image Generation
Step 1: Loading the Model and Text Encoders
- Open ComfyUI and load the workflow downloading from website Comfy-Org/stable-diffusion-3.5-fp8 at main, and create a TripleCLIPLoader node to load the text encoders(By default the loader already exist):
clip_g.safetensorsclip_l.safetensorst5xxl_fp8_e4m3fn_scaled.safetensors
- Connect the text encoders to the positive and negative prompt inputs.
- Load the Stable Diffusion 3.5 Large fp8 model (
sd3.5-large_fp8_scaled.safetensors) as the checkpoint.
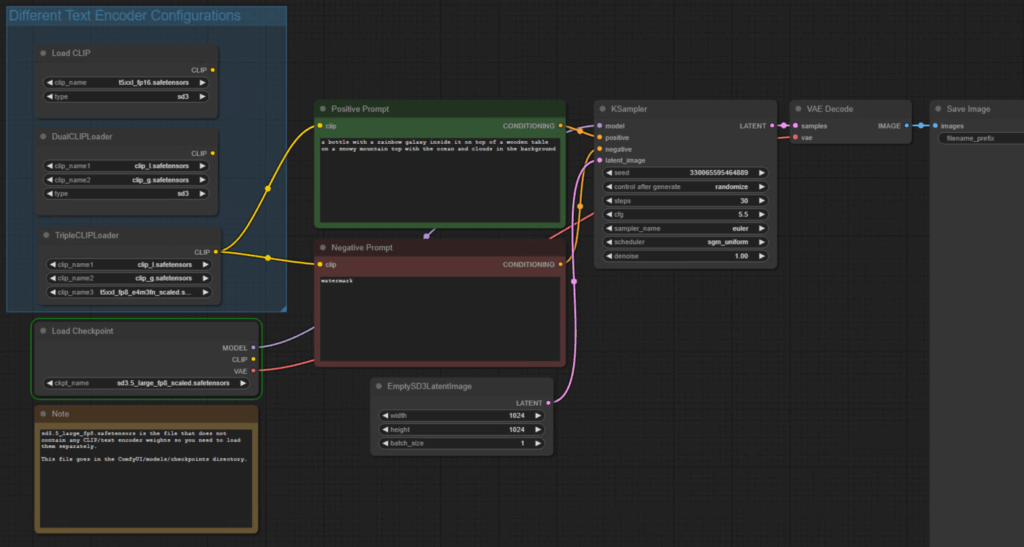
Step 2: Adjusting Model Settings
Stable Diffusion 3.5 Large Turbo is a distilled model, optimized for speed. Adjust the following settings for optimal results:
- Sampling Steps: Set the number of sampling steps to 4 to reduce generation time while maintaining quality.
- CFG Scale: Lower the CFG (Classifier-Free Guidance) scale to 1 for balanced image generation.
Step 3: Generating Images
- Enter a verbose prompt that leverages the advanced syntax understanding of the T5 encoder.
Example :A serene landscape with mountains in the background, a clear blue sky, and a flowing river, photorealistic, high detail. - Click Queue to execute the prompt.
- Note: The first image generation may take several minutes due to the large model size and encoders. Subsequent generations will be faster.

Key Considerations for Stable Diffusion 3.5
- Prompt Length:
- The T5 encoder supports up to 256 tokens, allowing for detailed prompts.
- However, the CLIP encoder limits prompts to 75 tokens, which may constrain complex descriptions.
- Hardware Requirements:
- While Stable Diffusion 3.5 Large Turbo is optimized for systems with limited video RAM, the initial setup may still require significant memory, especially for the T5 encoder.
- Output Quality:
- The model generates images at 1024×1024 resolution, providing high-quality results suitable for professional use.
Conclusion
Stable Diffusion 3.5 Large represents a significant step forward in AI image generation, offering faster performance and better prompt understanding. By following this guide, users can set up and use the model effectively with ComfyUI to produce stunning, high-resolution images. With additional refinements expected in future updates, Stable Diffusion 3.5 is a powerful tool for creators and developers alike.